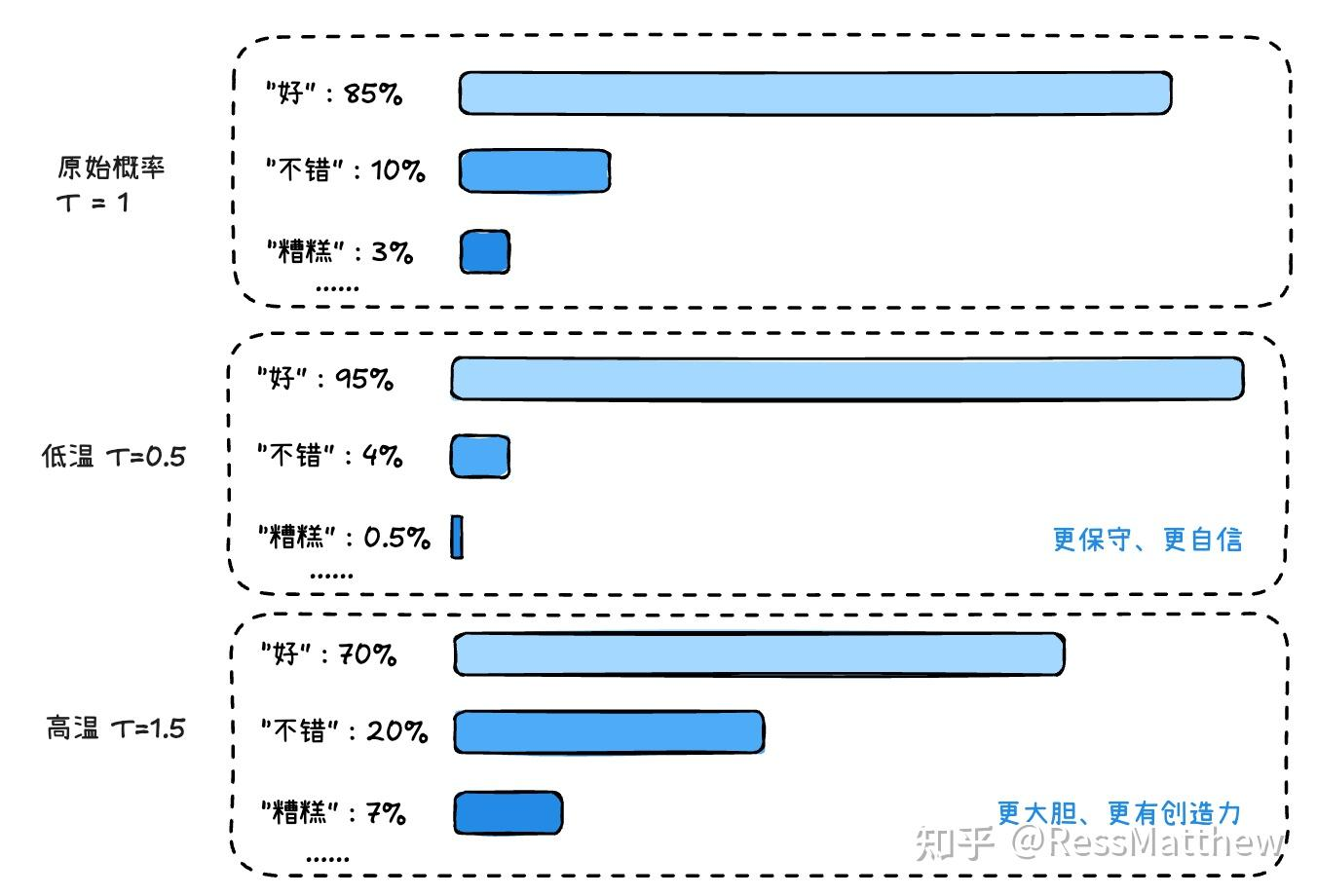
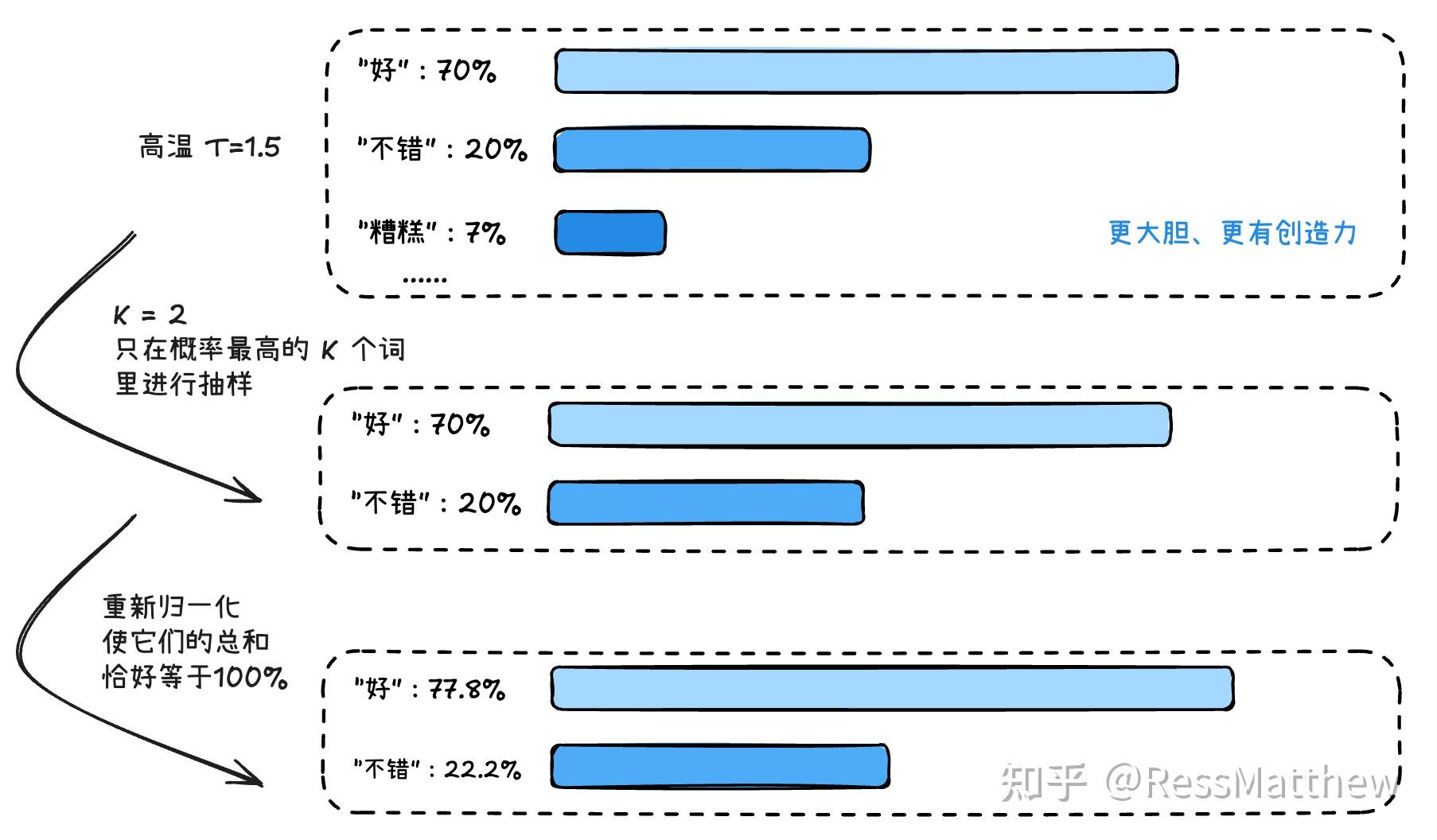
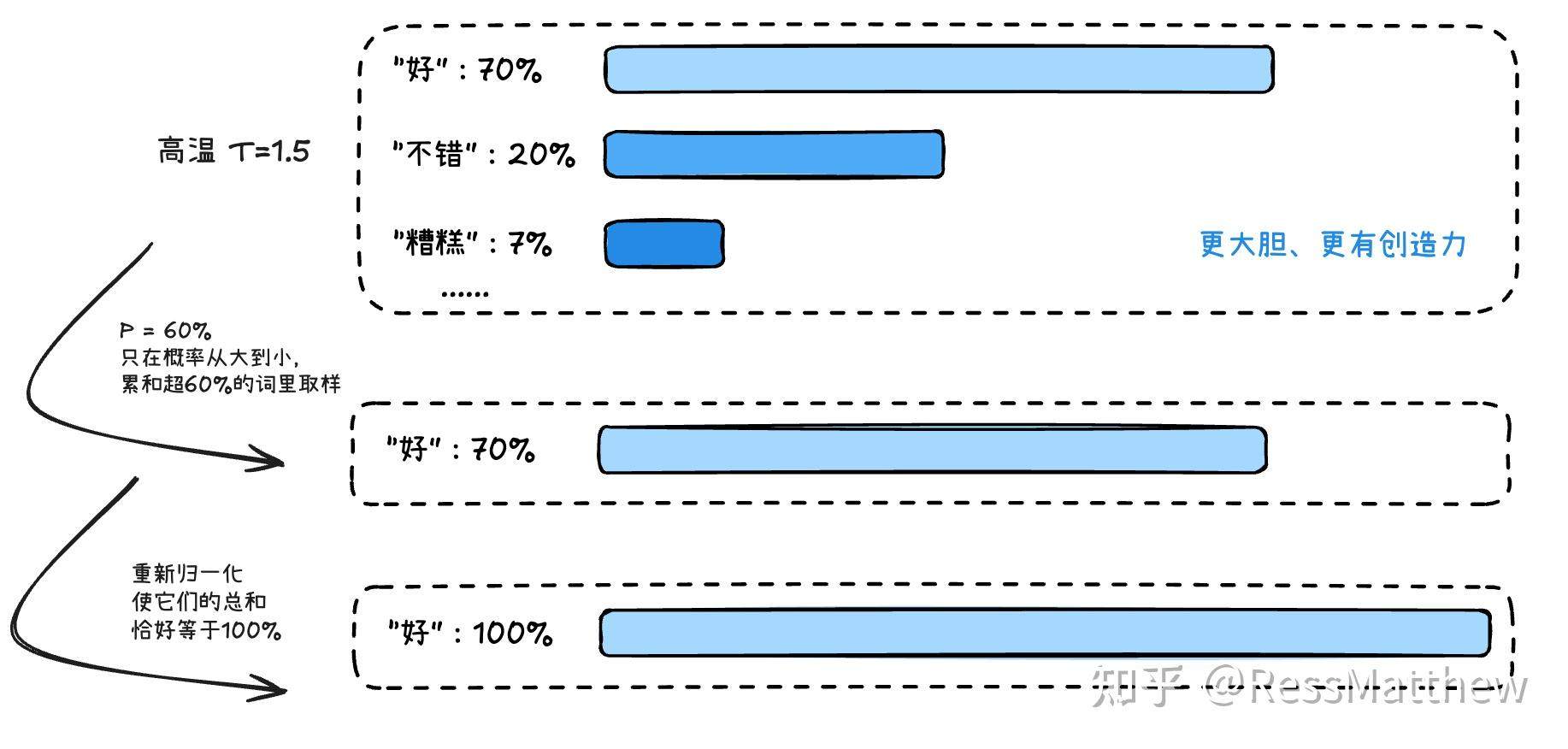
classTopKLogitsWarper(LogitsProcessor): r""" [`LogitsProcessor`] that performs top-k, i.e. restricting to the k highest probability elements. Often used together with [`TemperatureLogitsWarper`] and [`TopPLogitsWarper`].
Args: top_k (`int`): The number of highest probability vocabulary tokens to keep for top-k-filtering. filter_value (`float`, *optional*, defaults to -inf): All filtered values will be set to this float value. min_tokens_to_keep (`int`, *optional*, defaults to 1): Minimum number of tokens that cannot be filtered. """
def__init__(self, top_k: int, filter_value: float = -float("Inf"), min_tokens_to_keep: int = 1): ifnotisinstance(top_k, int) or top_k <= 0: raise ValueError(f"`top_k` has to be a strictly positive integer, but is {top_k}")
@add_start_docstrings(LOGITS_PROCESSOR_INPUTS_DOCSTRING) def__call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor) -> torch.FloatTensor: top_k = min(self.top_k, scores.size(-1)) # Safety check # Remove all tokens with a probability less than the last token of the top-k indices_to_remove = scores < torch.topk(scores, top_k)[0][..., -1, None] scores_processed = scores.masked_fill(indices_to_remove, self.filter_value) return scores_processed
classTopPLogitsWarper(LogitsProcessor): """ [`LogitsProcessor`] that performs top-p, i.e. restricting to top tokens summing to prob_cut_off <= prob_cut_off. Often used together with [`TemperatureLogitsWarper`] and [`TopKLogitsWarper`].
Args: top_p (`float`): If set to < 1, only the smallest set of most probable tokens with probabilities that add up to `top_p` or higher are kept for generation. filter_value (`float`, *optional*, defaults to -inf): All filtered values will be set to this float value. min_tokens_to_keep (`int`, *optional*, defaults to 1): Minimum number of tokens that cannot be filtered. """
def__init__(self, top_p: float, filter_value: float = -float("Inf"), min_tokens_to_keep: int = 1): top_p = float(top_p) if top_p < 0or top_p > 1.0: raise ValueError(f"`top_p` has to be a float > 0 and < 1, but is {top_p}") ifnotisinstance(min_tokens_to_keep, int) or (min_tokens_to_keep < 1): raise ValueError(f"`min_tokens_to_keep` has to be a positive integer, but is {min_tokens_to_keep}")