注意力机制
1. General Attention Model
A General Survey on Attention Mechanisms in Deep Learning - 2023
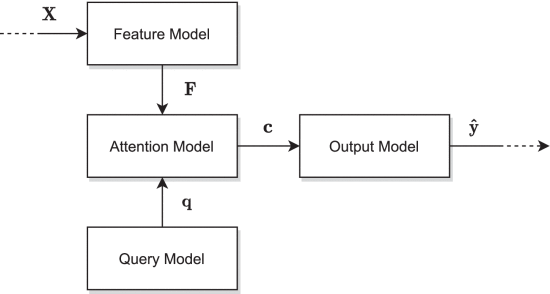
input matrix:
feature model: extract features from input matrix
to get feature vectors query model: extract query to
attention model: extract
matrices from , , . - Key:
- Value:
- Key:
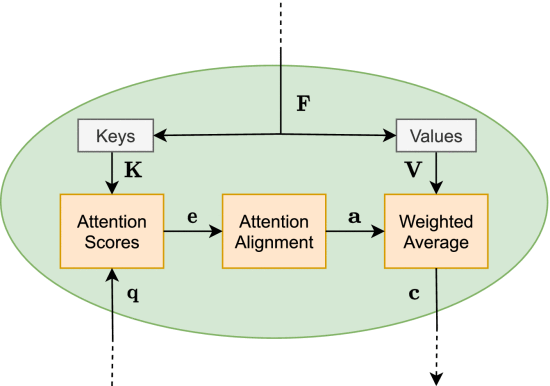
, eg. softmax , output model
2. Self-Attention
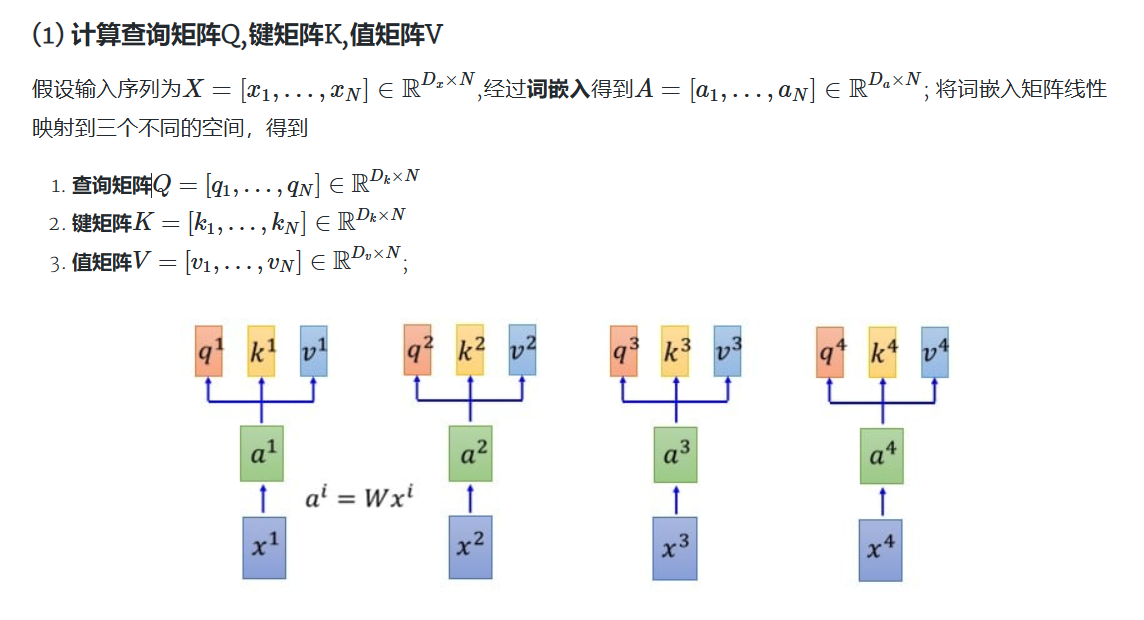
线性自注意力机制
传统自注意力机制计算复杂度为
scale dot-product attention:
softmax的存在使得QK计算得到
实现这种线性自注意力有以下方法
- 添加核函数,为保证qk乘积不为负,添加核函数,例如给q,k添加relu函数,确保非负
- 对Q在d的维度上进行softmax, 对K在n的维度上进行softmax,则
目前的主流开源LLM,如LLama,GLM,Qwen,都是基于传统自注意力机制,RWKV系列模型使用了线性自注意力机制
稀疏自注意力机制
在注意力计算上,只计算一部分的QK,使得计算复杂度降低。
Flash Attention
通过分块计算减少显存的读写次数,提高计算效率
KV Cache
在计算Attention时,将KV缓存,减少计算量,LLM的自回归性质每个token的生成都需要计算历史token的Attention,直接复用缓存可减少计算量。
1 | |
MQA, MHA, GQA
- MHA: Multi-Head Attention
- GQA: Global Query Attention
- MQA: Multi-Query Attention
MHA, 每个head有单独的KV。GQA,所有head分为多个组,组内共享一个KV。MQA,所有head共享一个KV。
- MHA_MQA_GQA.md
- CSDN 一文通解GQA
- GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints
MLA
MLA即Multi-Head Latent Attention,由DeepSeek在V2模型中提出,使用了低秩矩阵 key-value的联合压缩来解决推理时KV Cache的内存瓶颈问题。
MLA的计算公式如下:
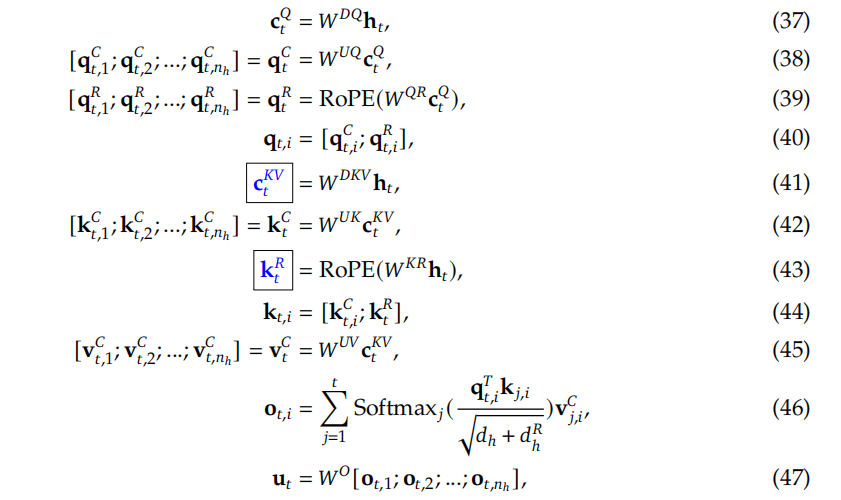
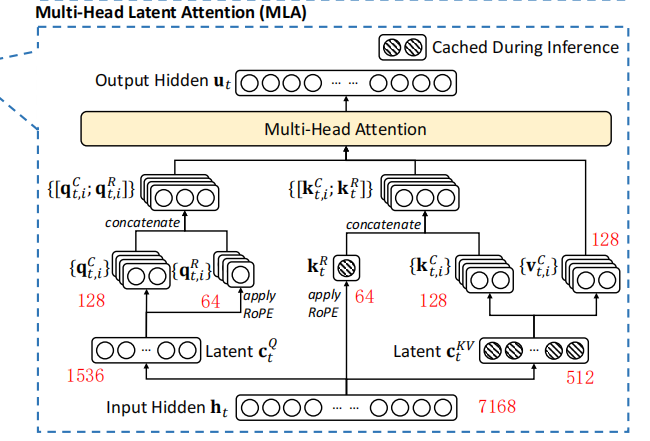
MLA在推理时只缓存KV联合压缩后的矩阵
注意力机制
https://wenzhaoabc.github.io/llm/attention/