港科广LLM讲座
港科广LLM讲座
包括五部分内容:
- Resource Efficient LLM Fine-tuning
- Qwen:Towards a GeneralistModel
- LLM Evaluation andSafety at Naver
- Challenges and PracticalApproaches to Design Privateand Scalable Information DataManagement Systems
- Unlocking Generative Al withUbiquitous HW and Open SW
- OCR for LLM
1. Resource Efficient LLM Fine-tuning
术语 :
- PEFT:Parameter-Efficient Fine-Tuning(高效参数微调)
- LoRA:Low-Rank Adapter(低秩适配器)
- PEQA:Parameter-Efficient Quantization Aware Fine-Tuning(高效参数量化感知微调)
- QLORA:Quantization-Aware Low-Rank Adapter(量化感知低秩适配器)
1. 为什么需要PEFT

2. PEFT的进展

3. 模型微调的若干方法

Prefix : 在输入序列前加入一个特定的前缀,如“translate English to Chinese:”。
Adapter fine-tuning : 在原模型的中间层加入一个adapter层,只训练adapter层。最早来源于论文《Parameter-Efficient Transfer Learning for NLP》
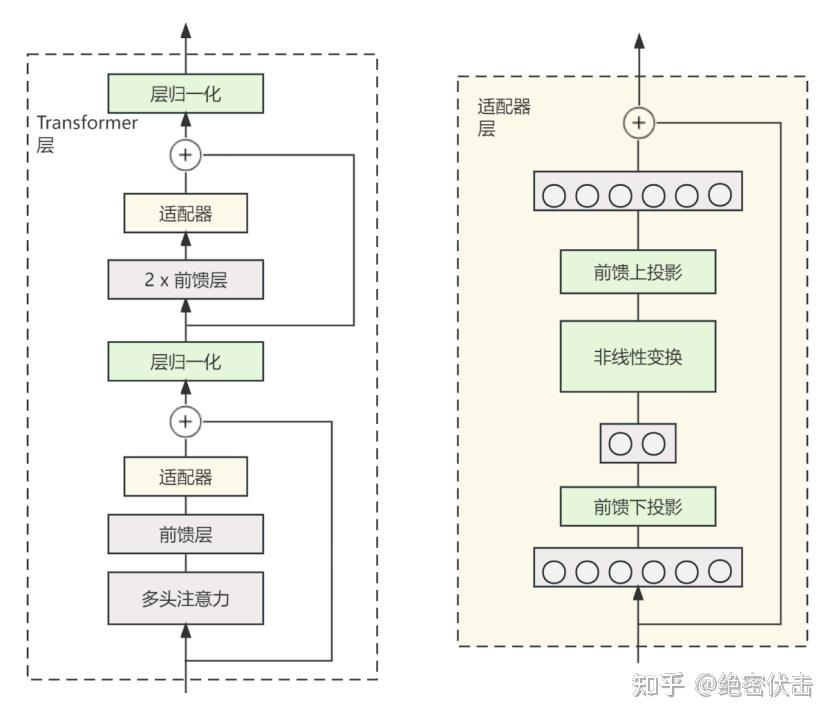
LoRA : 使用低秩分解矩阵. 论文.
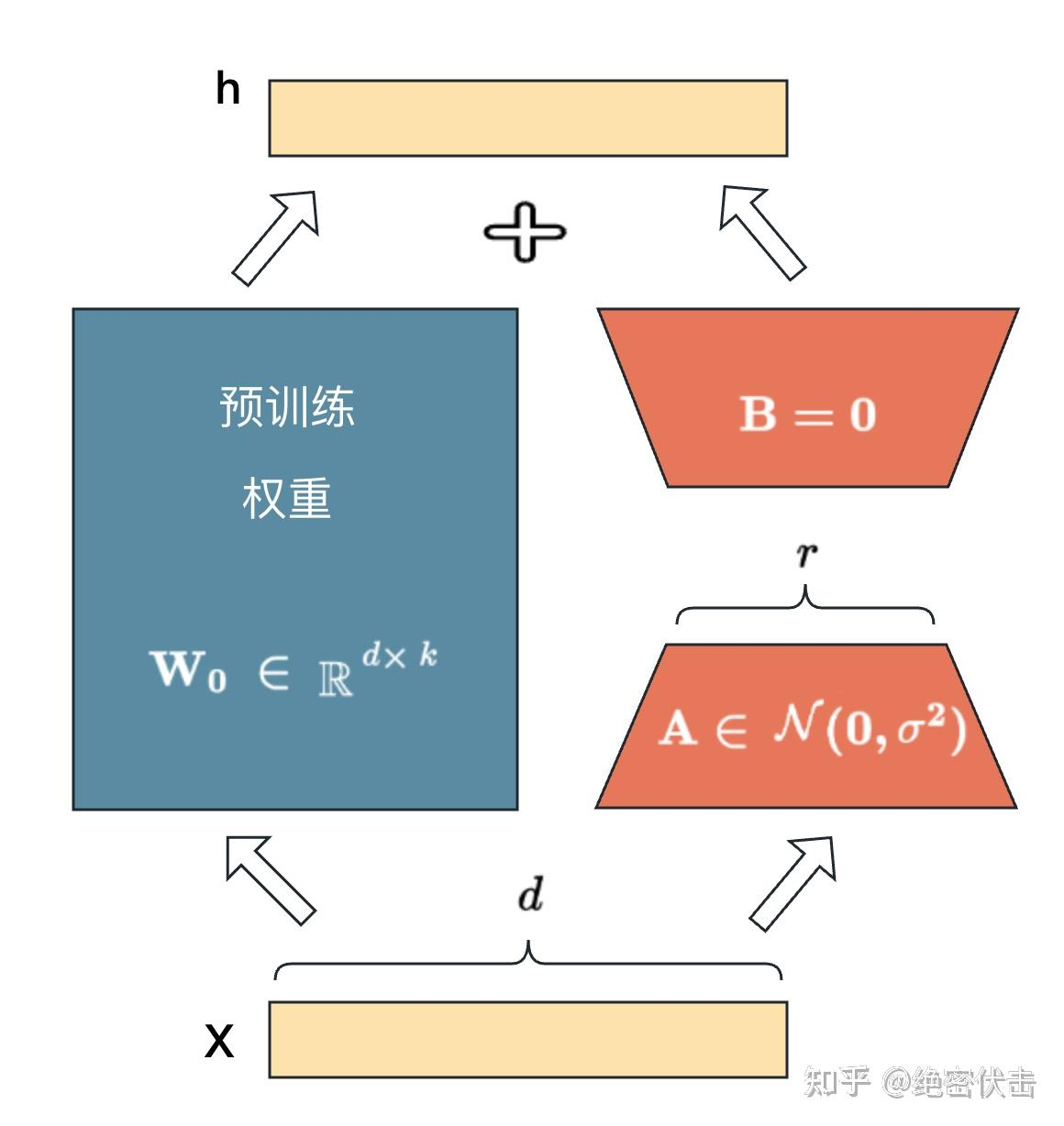
在原始PLM (Pre-trained Language Model) 旁边增加一个旁路,做一个降维再升维的操作来模拟所谓的 intrinsic rank。训练的时候固定 PLM 的参数,只训练降维矩阵A与升维矩阵B。而模型的输入输出维度不变,输出时将 BA与 PLM 的参数叠加。用随机高斯分布初始化 4 ,用 0 矩阵初始化 B,保证训练的开始此旁路矩阵依然是0矩阵
- FISH Mask : 使用参数的FISH信息来计算掩模。
4. 模型压缩
- QLORA : 将模型量化为4位精度并使用分页优化器。QLORA:高效微调量化LLM
4位NormalFloat(NF4)- 一种新的数据类型,对于正态分布的权重来说在信息论上是最优的。
双重量化 - 通过量化量化常数来减少平均内存占用。
分页优化器 - 用于管理内存峰值。
- PEQA : 采用了双阶段过程运行。在第一阶段,每个全连接层的参数矩阵被量化为低比特整数矩阵和标量向量。在第二阶段,对每个特定下游任务的标量向量进行微调。论文:Memory-Efficient Fine-Tuning of Compressed Large Language Models via sub-4-bit Integer Quantization
5. PEFT的两大类
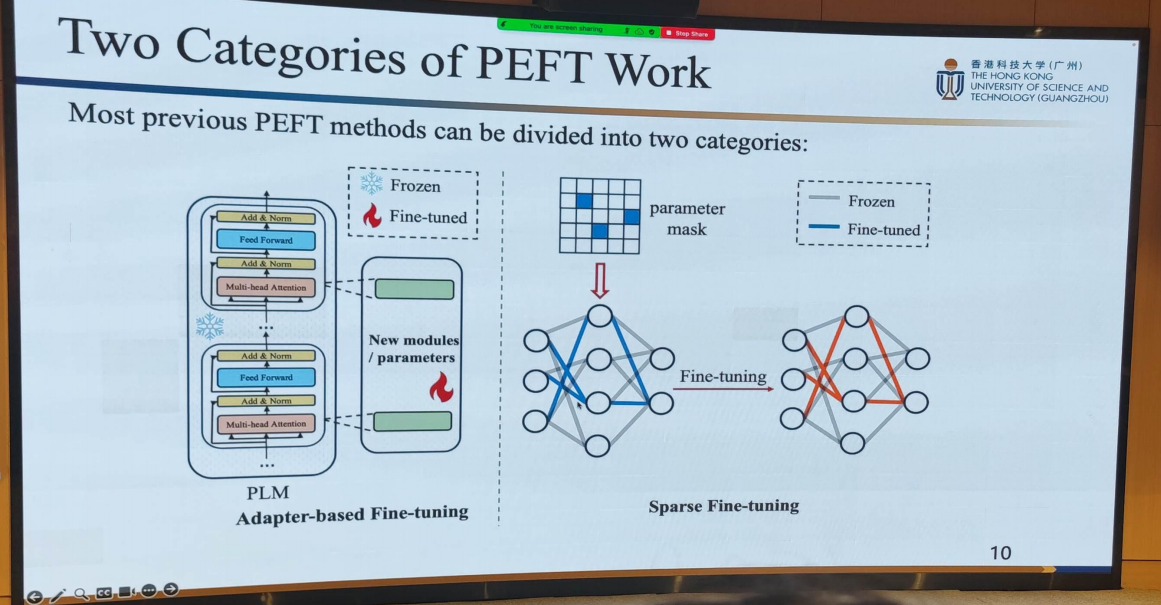
- Adapter-based Fine-tuning
- Sparse Fine-tuning
6. Limition

7. 作者的方法
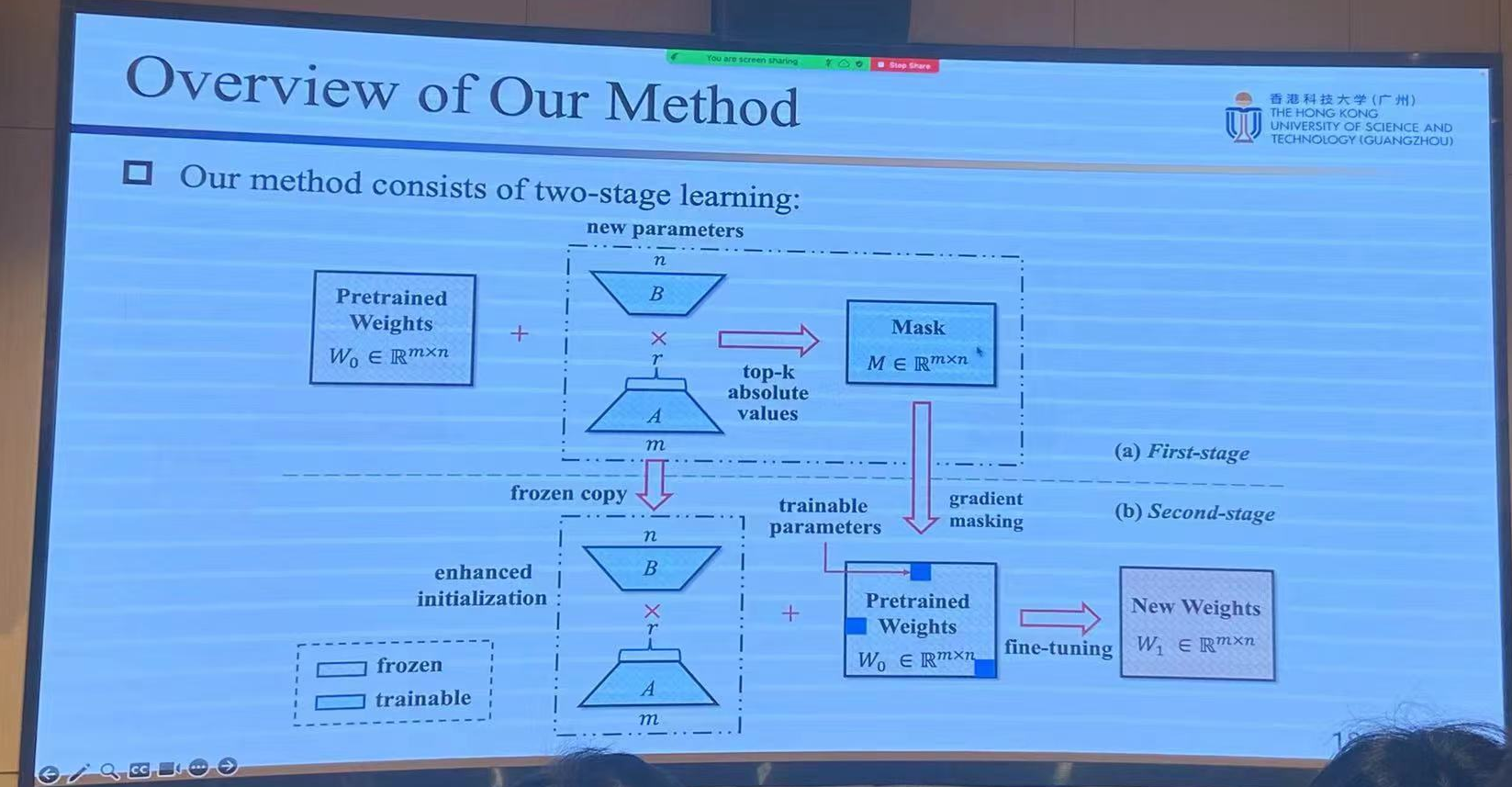
实验结果:

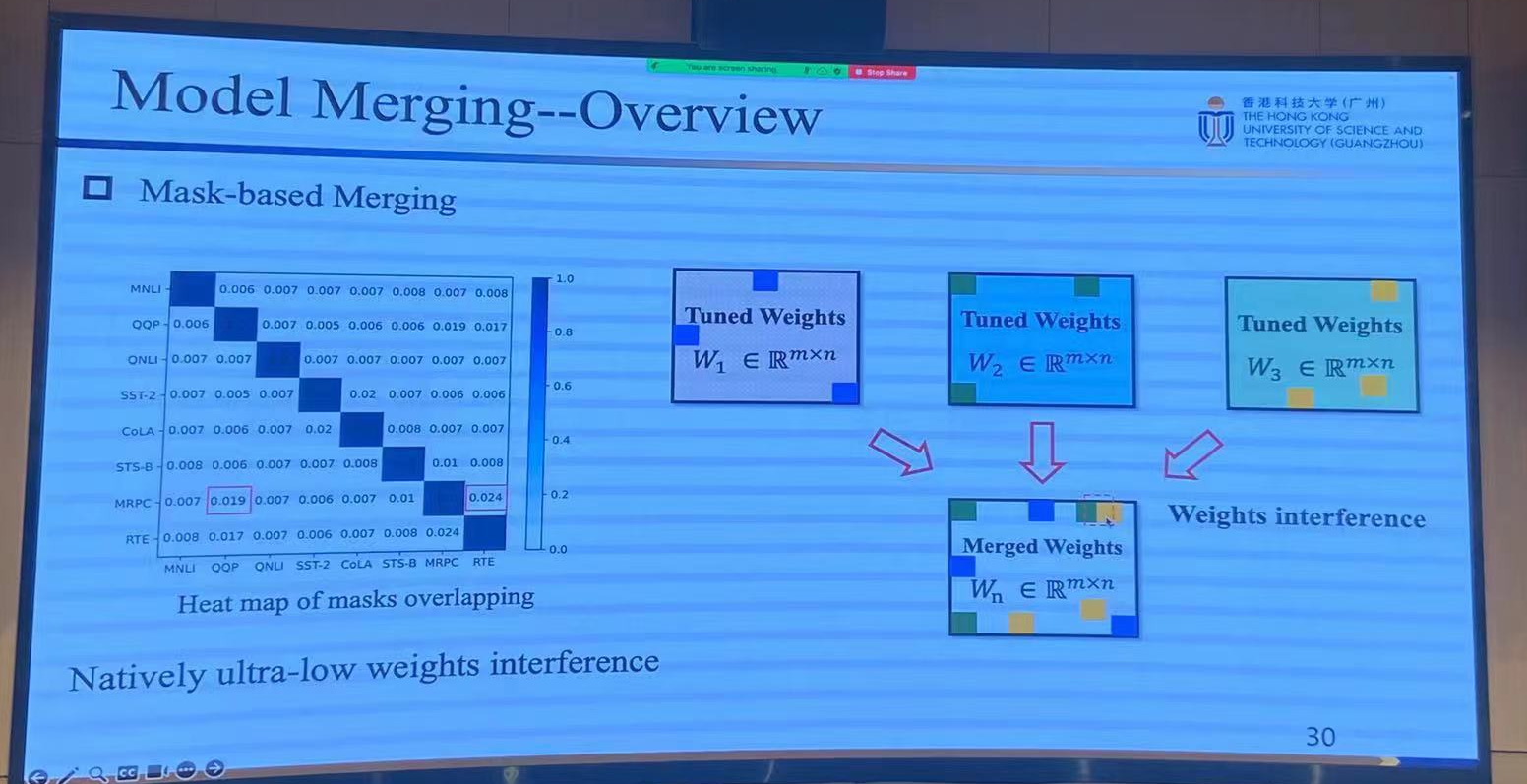
前瞻:Model Merging

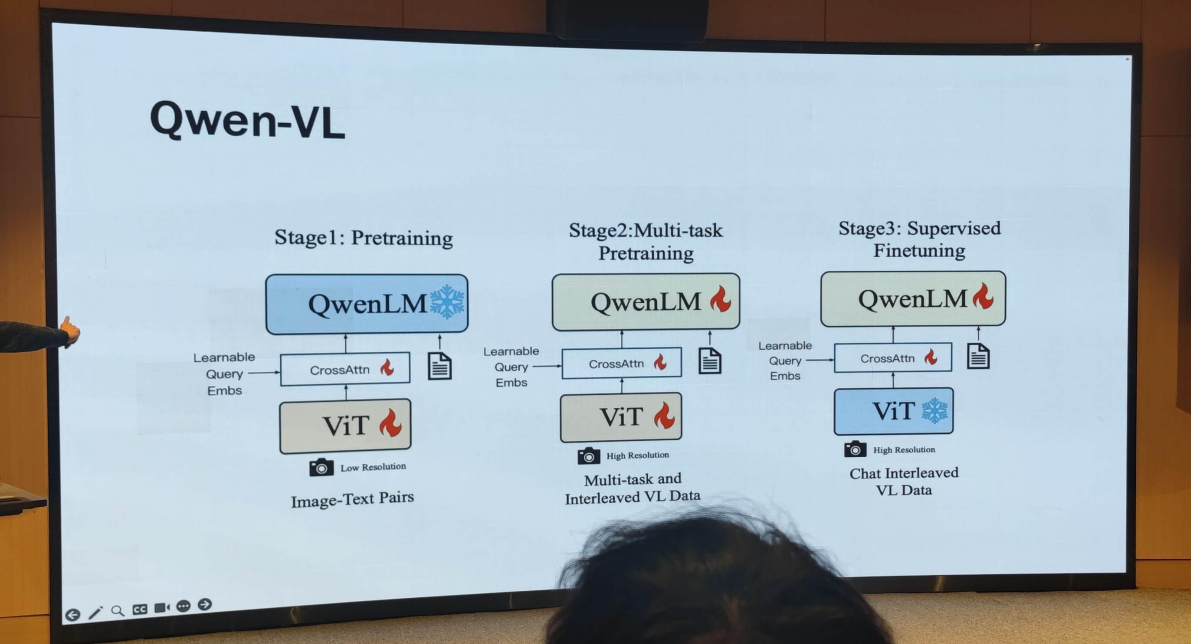
2. Qwen:Towards a GeneralistModel

3. LLM Evaluation and Safety at NAVER

Why

Challenges of (Human) LLM Evaluation

敏感问题

How
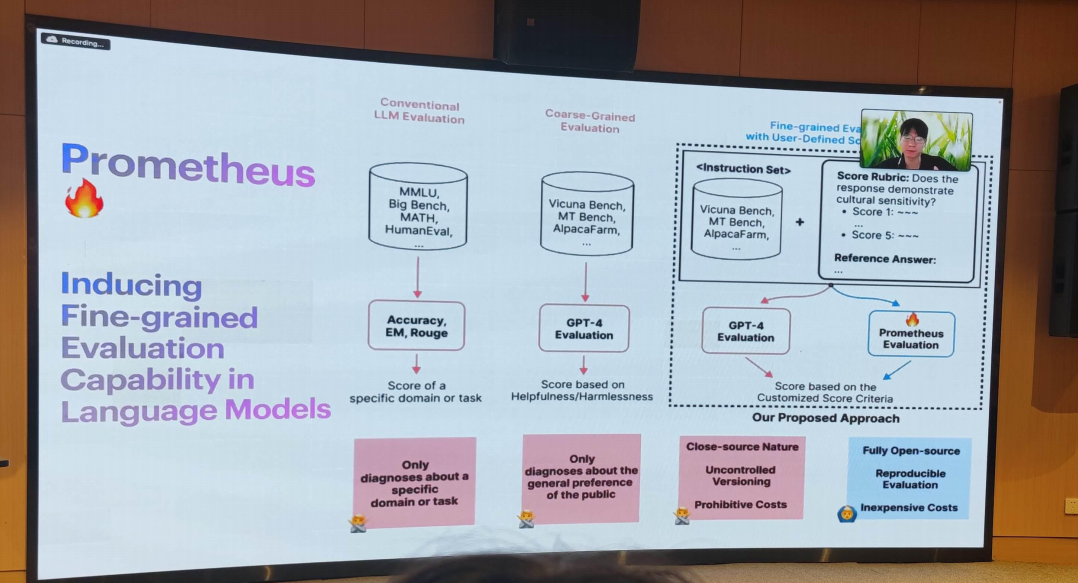
- Prometheus
在语言模型中引入细粒度评估能力.

- SQuARe
这篇论文主要关注大型语言模型可能带来的社会危害,如生成冒犯性内容和强化偏见。尽管现有的工作主要集中在与恶意用户交互时应对这个问题,但即使用户的初衷是好的,讨论敏感问题也可能变得有毒。为了在这种情况下有更安全的模型,论文提出了一个名为SQuARe(Sensitive Questions and Acceptable Response)的数据集,这是一个大规模的韩语数据集,包含49k个敏感问题以及42k个可接受和46k个不可接受的回答。
- KoSBi
KoSBi: A Dataset for Mitigating Social Bias Risks Towards Safer Large Language Model Application
这篇论文主要关注大型语言模型(LLMs)从现实世界的数据中学习自然文本生成能力的同时,也学习了针对不同人口群体的社会偏见,这在部署基于LLM的应用时构成了重要风险。由于语言和文化的差异,现有的研究和资源在韩国并不容易应用,这两个因素都显著影响了偏见和目标人口群体。这种局限性需要本地化的社会偏见数据集,以确保LLM的安全有效部署。为此,论文提出了KO SB I,这是一个新的社会偏见数据集,包含34k对韩语的上下文和句子,涵盖了15个类别的72个人口群体。研究发现,通过基于过滤的调节,可以将HyperCLOVA(30B和82B)和GPT-3生成内容中的社会偏见平均减少16.47%。
4. Challenges and PracticalApproaches to Design Privateand Scalable Information DataManagement Systems
ORAM : Oblivious Random Access Machine (不经意随机访问机)
ORAM(Oblivious RAM)是一种隐私保护技术,用于在云存储等场景中保护用户数据的隐私。它通过在访问存储时隐藏访问模式,以防止任何有意或无意的信息泄露。

几种实现方式
- PATH ORAM : 通过树状结构实现,每次访问时都会将整个路径上的数据重新加密并重新排列,以隐藏访问模式。
- Cuckoo ORAM : 通过哈希表实现,每次访问时都会将数据重新加密并重新排列,以隐藏访问模式。
- Ring ORAM : Ring ORAM 是一种基于环形结构的ORAM方法,通过将数据存储在环上并以随机的顺序进行排列,以隐藏访问模式。这种方法通常比Path ORAM具有更低的复杂度。
5. Unlocking Generative Al with Ubiquitous HW and Open SW
Intel 大模型AI开发团队
Intel NeuralChat - https://huggingface.co/Intel/neural-chat-7b-v3-3

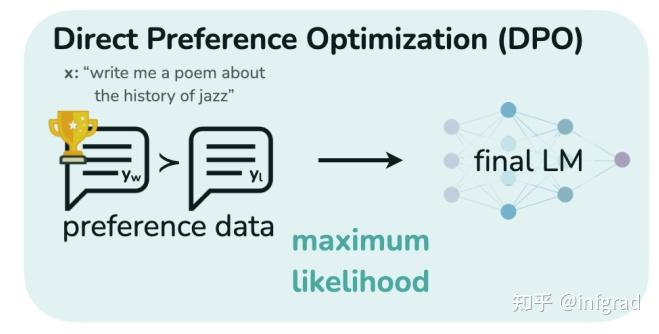
基于Mistral-7B,使用开源数据集SlimOrca,使用DPO(Direct Preference Optimization)算法进行对齐. 对齐的详细介绍:Supervised Fine-Tuning and Direct Preference Optimization on Intel Gaudi2
- Intel Extension For Transformers :
- Intel Gaudi2加速器 : 深度学习计算卡
- DPO算法 : 引导LMs匹配人类偏好,DPO/RLHF DPO
- Intel Neural Compressor
- SignRound:New INT4 LLM Quantization Recipe
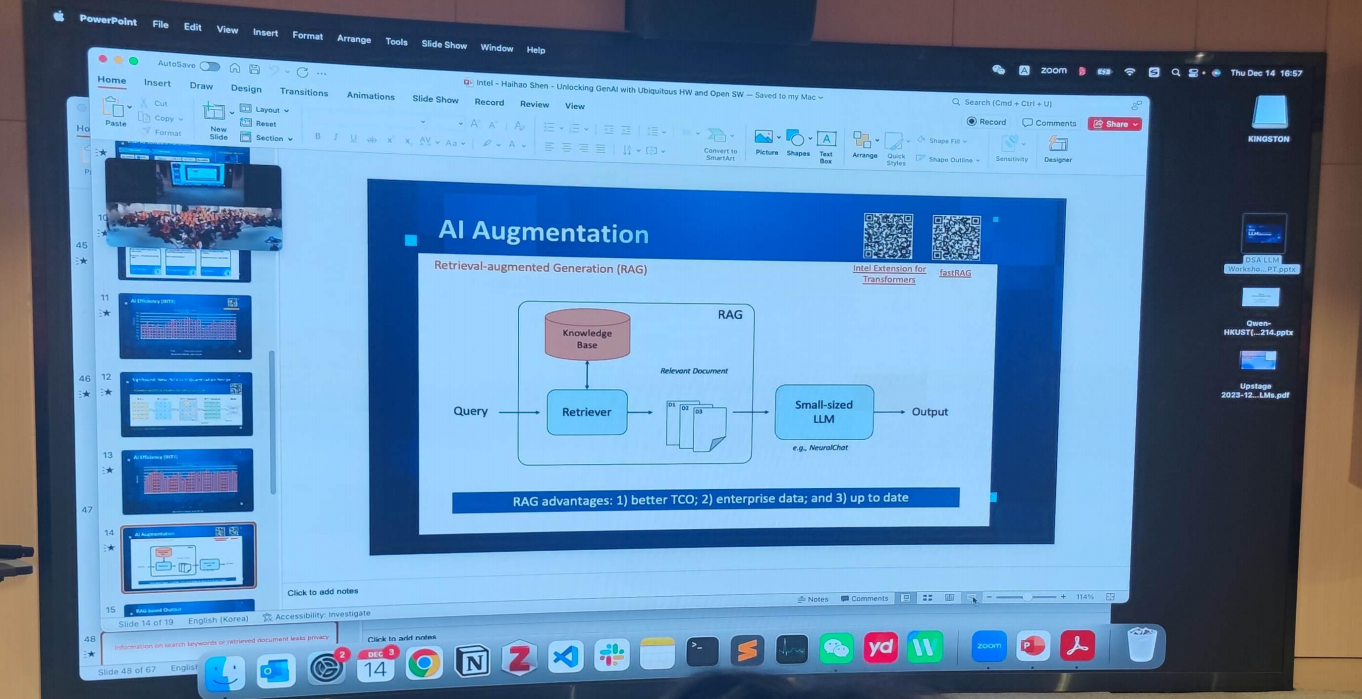
- Al Augmentation
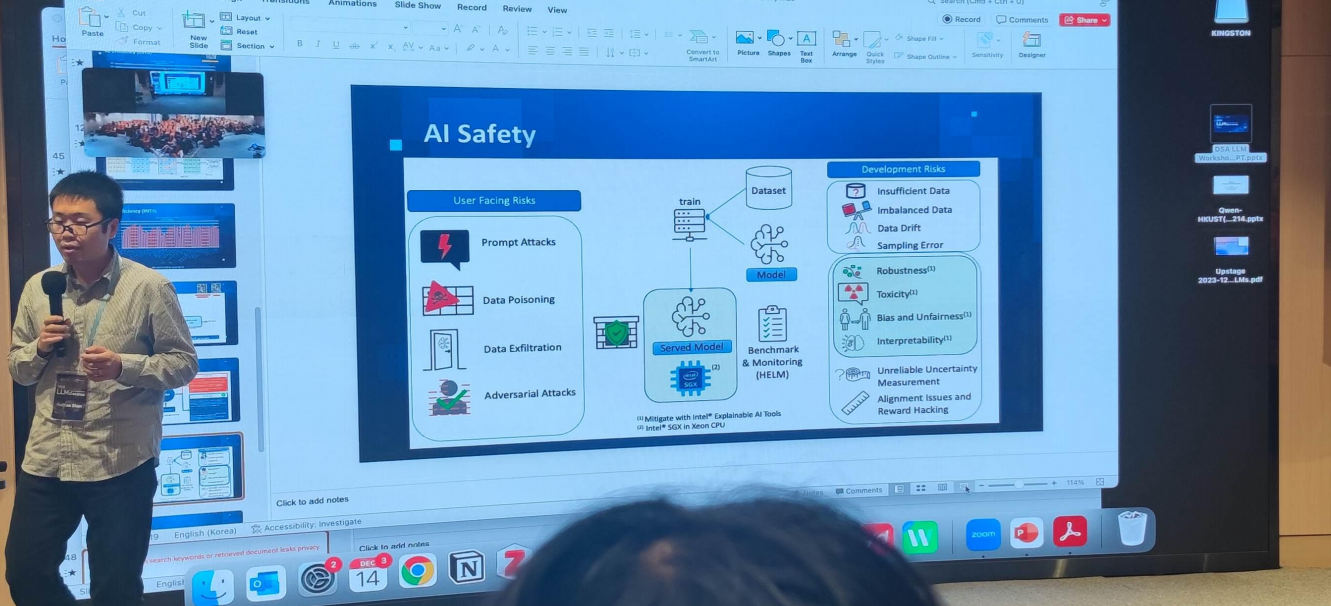
- AI Safety
6. OCR for LLM
- LLM Stack

- Input and Output

- Modules of OCR for LLM
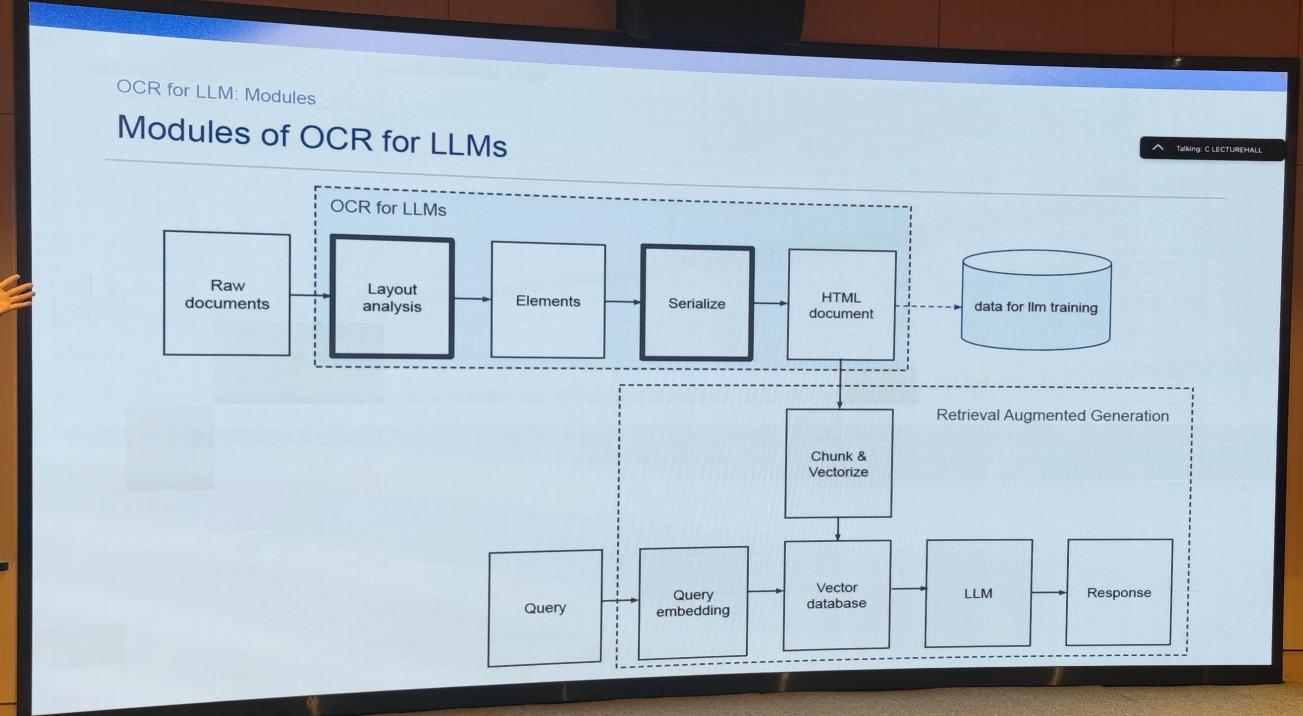
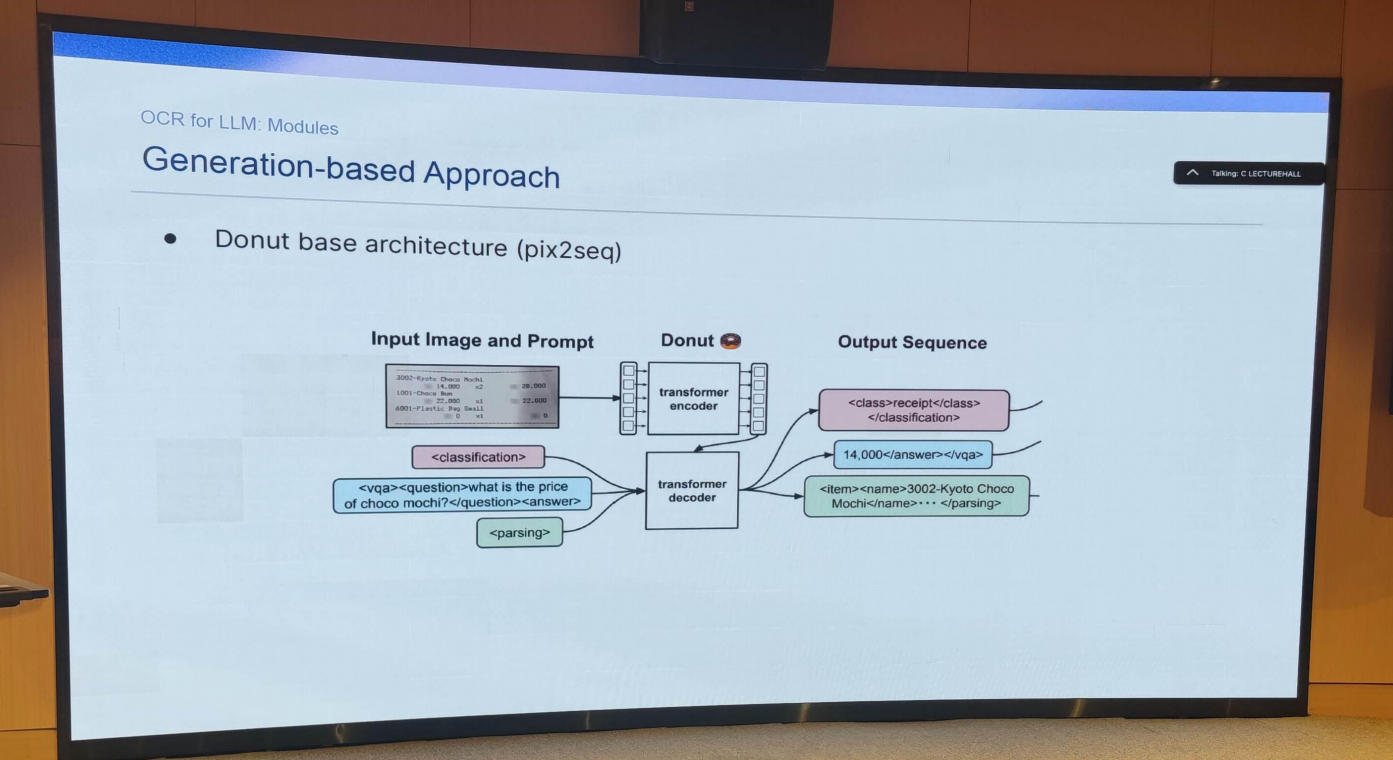
- Requests for research

- 多任务学习在布局分析和序列化中的应用。而不是使用单独的模型来进行布局分析和序列化,而是开发一个统一的模型。它可以是一个生成模型,如donut,但应该在质量和速度方面更优越。
- 序列化评估度量的开发。什么才是定量评估阅读顺序的一个很好的衡量标准?地图,准确性,蓝牙吗?它也适用于长文档吗?
- 信息图形文本。以文本格式表示信息图形和/或图像的最佳方式是什么。图像字幕是最具代表性的格式吗?